

How to Fix Turk Instructions Tasks


Note this is a "draft" of notes, but I think they're still helpful to start. Sorry if they're messy, I haven't cleaned them up yet but I thought it'd be valuable to just give this in your hands for now early and edit/polish it later as needed
When making edits to batch.csv for tasks, especially if resolving the retrieve_gold_labels error and you end up editing the number of unique tasks, you will error in the len(distinct rows) thingy. Go to 4_run_evaluation and search up TODO assert, I made it like that TODO assert for easy look up and comment out that assertion. Don't forget to put it back in!
Can run clean_csv from the root of turk-instructions, configured that way and just go python src/utils/clean_csv.py. Try to understand the other helper functions already written, I basically just copy paste them now with slight modifications since they're quite diverse and cover a lot of the times you'd need to do data cleaning. Cleaning_csv is mostly good for when you need to change outputs from like "true" to "on" for checkboxes, or if the Answer is like Answer.1-1 Answer.1-2 and one of them is true, other is false, where the answer value should actually be 1 or 2, not under these columns one being true
Nice CSV editor super important. On Linux you can use LibreOffice Calc, Excel and Sheets are great too. Freeze the first row, and go hunting!
I created run_single to easily develop a task at the time. I configured it so that you just need to touch the global variables at the top, RUN_ALL turns on headless for example. During run-all, as long as an error doesn't occur it will tell you the index on the first failure too.
Retrieve gold labels usually failures occur when answers maps are like [] empty. This is because you weren't able to find any inputs matching the instance input, so some undefined equality things occurred like empty

If you actually print the cols
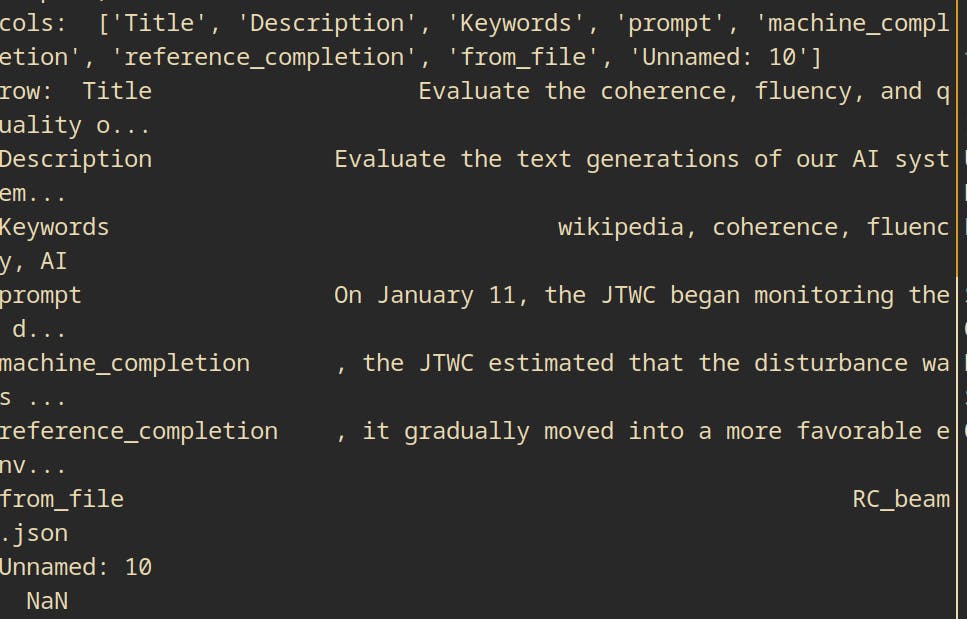
See a NaN here and a weird column Unnamed: 10. It was an empty CSV column hidden causing issues, probably an extra comma or something in CSV

Deleting this resolves it (https://github.com/JHU-CLSP/turk-instructions/pull/91/commits/5b055cc30b742725f0be246d367e8ed8c5e2772e)
Explanation how retrieve gold labels work:
Retrieve gold labels works by you passing the row number of the task ID you are solving right now, and then it goes ahead and grabs all rows in batch.csv that have the exact same input as the task ID. Then it polls all the answers of the task ID and returns ALL the answers. This is useful since for some questions we have multiple responses, we can return ALL of those answers as valid answers (instead of the result from just one row). This makes sense since there may be multiple right answers, or its subjective. We just want the model to be close to at least one of these answers since that means a human evaluator that was the correct answer as well.
I changed the code base in <this PR> so oracle now completes in the order of the columns. This is problematic as traditionally the columns are sorted in lexographic order, so Answer10 goes before Answer2. This is bad if oracle needs to care about answers, like certain answers before others. Reordering the columns are great
Filter TAP tasks are amazing, keep appending skipped tasks to that helper function
GitHub actions TAP tests I created are great. Tell you instances you fail, tip is to actually view them in localhost:8000/instance/instance_num so you can see if inputs aren't doing well and stuff like that
Sometimes if you pass like 500 instances and only fail 1, and the one you fail is the very last one, there are some hidden values in that last row that make it think its another instance. Just go delete the last row. Same is said for any row in the middle, like for this task Word Formality only row 28 was failing out of 107, my tip is to check that instance_id and plug it into the URL

Like here the instance_id is 33978, so plug that into the URL http://localhost:8000/task/33978 and here you see that the task is deformed since the inputs are all empty as well. Just delete those rows
4_run filter_tap_tasks use the arrays created, skip weird ones and report skipped
Sometimes you'll encounter a string of red "Could not find input field with name" like this for the task wikiHow step-goal linking pilot cleanse-url:
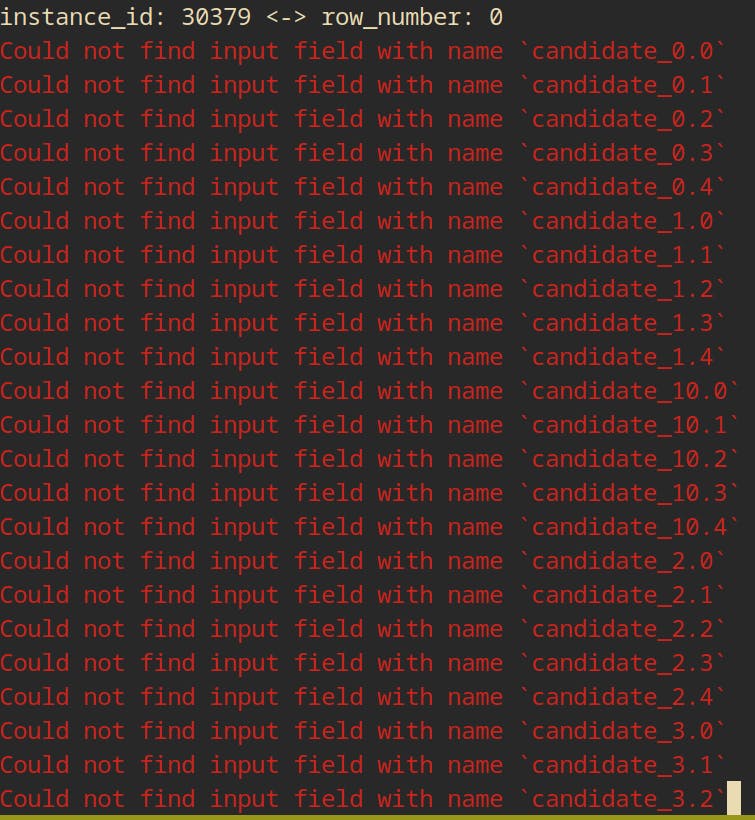
The way to address these issues is to analyze the HTML for the task and look for the input fields that the batch.csv thinks is supposed to be candidate_3.0 for example
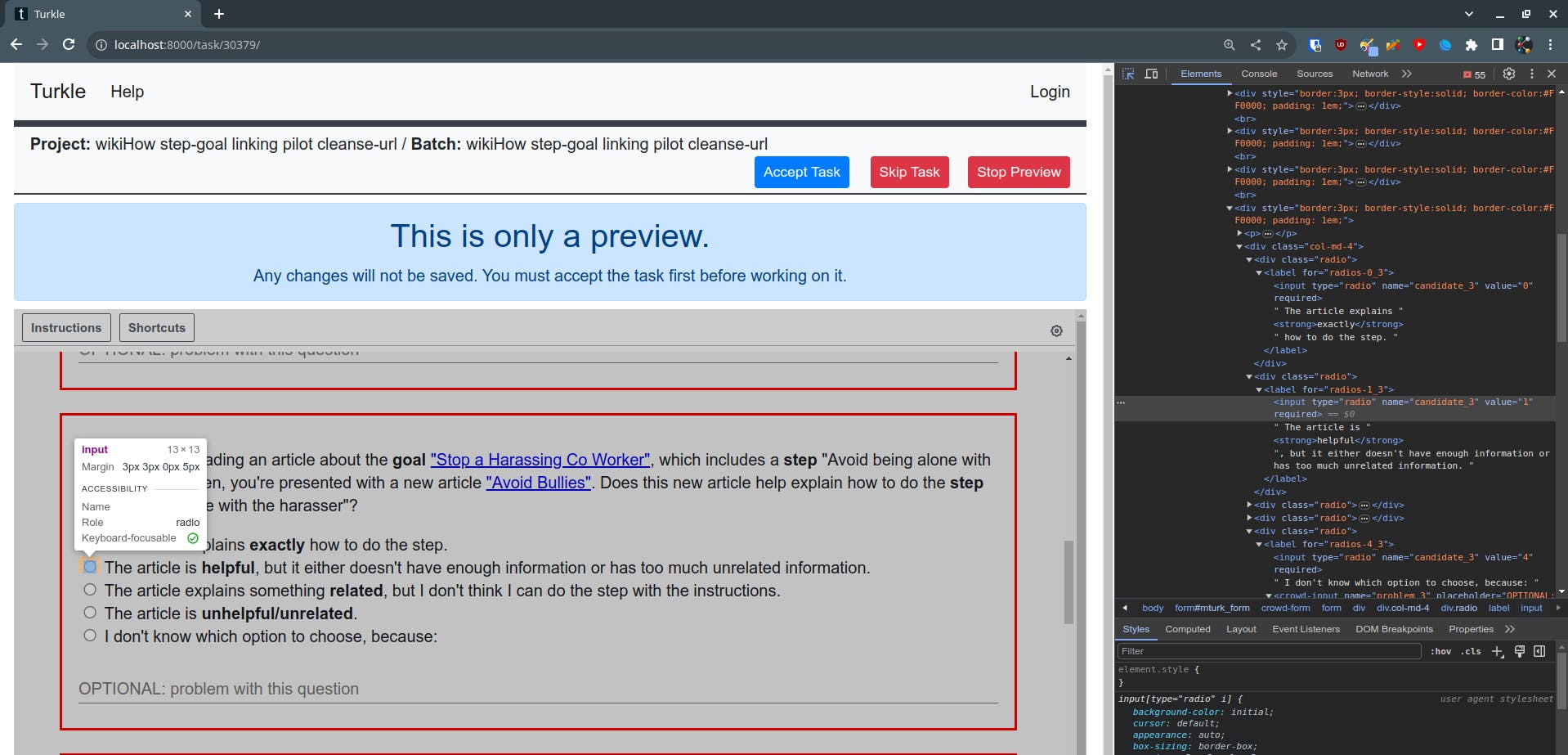
Here it looks like this, which is an input of candidate_3 has a value of 0, 1, 2, 3, and 4. However, if you look at the batch.csv

You'll notice that for each group of Answer.candidate there is one True and the rest are False. The correct mapping is probably just Answer.candidate3 and for that row the value is 0, instead of being True for 3.0 and false everywhere else. You can use my clean_split_up_radio function to solve this that I've coded to clean up problems like this for multiple tasks.
Additionally, if you have an instance in GitHub TAP tests where you fail a few instances out of total. Go hunt for those instance numbers in your URL, it'll be the first instance + that row_num and just delete those inputs tbh since it's likely those inputs are faulty and we don't need all the rows per task, just like 50 to train
